
Introduction
Since last year, I have wanted to find more ways to integrate AI into my blog. So far, I’ve used AI to help write posts, research posts, cross-post, and generate hero images. Of those, cross-posting is the only process that runs fully autonomously. To enrich the site experience and require less manual input from me, I came up with the idea of using embeddings to find similar posts for each article.
One idea I had was to use embeddings for creating a „Similar Posts“ component. The idea was inspired by Hashnode’s „More Articles“ component displayed at the bottom of posts.
The Hashnode component is interesting, but it seems to only display the three most recent articles. While taking some visual inspiration from it, my „Similar Posts“ component instead uses text embeddings and cosine similarity calculations to select the three articles to display.
Understanding the AI Approach
First, let’s clarify something. What is an embedding? For those who are unaware, OpenAI defines an embedding as follows:
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
With respect to my „Similar Posts“ feature, I will be converting each post to a vector. Then I will compare each vector to all the others by calculating their distances to each other.
In other words, the technique will be:
- Calculate embeddings for all articles by passing each article’s text to an embedding model.
- Compare the embedding for the given article with the embeddings of all other articles using cosine similarity.
- Select the articles corresponding to the top three embeddings with the closest cosine similarity.
To help visualize this, I have created the following diagram:
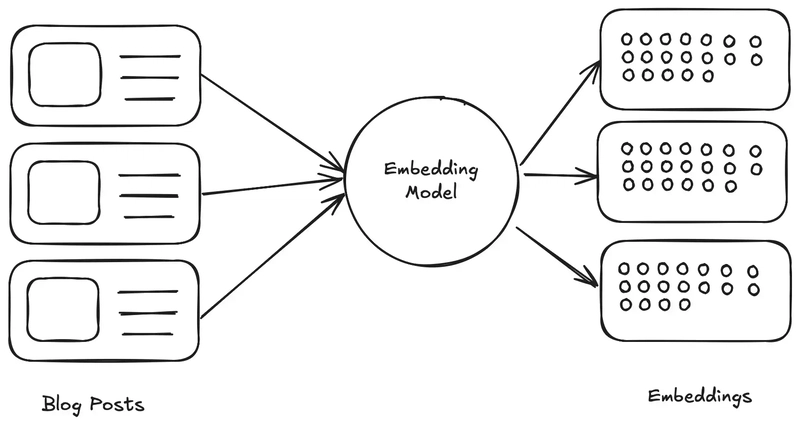
In summary, the embedding model can be thought of as a function. The model takes text as an input, and returns an array of numbers which represent a vector within the space of the model. To mirror this functional thinking, I defined the following types to represent my blog posts as inputs and outputs:
// The PostContent will be our input.
type PostContent = {
slug: string;
content: string;
};
// The Embedding will be our output.
type Embedding = {
slug: string;
vector: number[];
};
For the embedding model, I decided to use OpenAI’s embeddings API with the text-embedding-3-small model. To make things clearer, here’s a diagram representing how posts will be converted to embeddings:
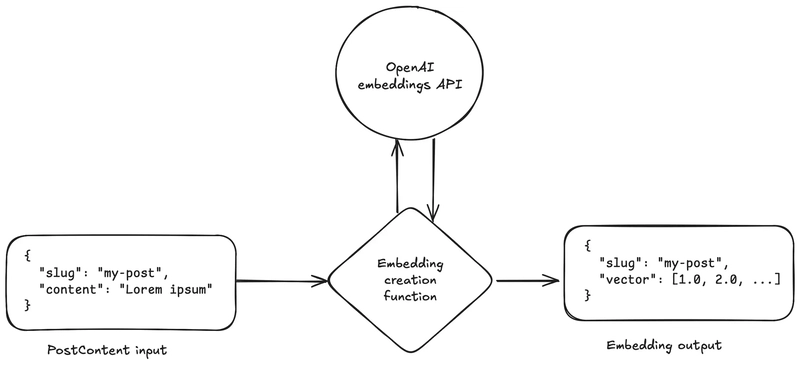
Now let’s move on to how I actually implemented this in code.
Generating Similar Post Data
After defining the two types above, I added them to my src/utils/openai.ts file. Then I defined a new function getPostEmbedding:
// src/utils/openai.ts
type PostContent = {
slug: string;
content: string;
};
type Embedding = {
slug: string;
vector: number[];
};
const getPostEmbedding = async (apiKey: string, post: PostContent): Promise<Embedding> => {
const openai = getClient(apiKey);
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: post.content
});
return {
slug: post.slug,
vector: response.data[0].embedding,
};
};
The getPostEmbedding function is pretty simple. It just takes the text of the post, sends it to OpenAI’s API, and then returns the resulting embedding. Next, I needed to pass each post to the embedding function. With my site, I have one file which loads all the posts in to memory called src/data/tags-and-posts.ts. Here’s what I did:
// src/data/tags-and-posts.ts
const embeddings: Embedding[] = [];
for (let i = 0; i < posts.length; i ++) {
const post = posts[i];
// Other computations are done here, like tag grouping.
const embedding = await getPostEmbedding(import.meta.env.OPENAI_API_KEY || '', {
slug: post.id,
content: post.body || '' // NOTE: We're using post.body which is the raw markdown of the blog post
});
embeddings.push(embedding);
};
Next, I had to perform the cosine similarity calculations. To handle this, I created a new file src/utils/related-posts.ts and added the following code:
// src/utils/related-posts.ts
const getCosineSimilarity = (vectorA: number[], vectorB: number[]) => {
// See https://stackoverflow.com/a/64816824 for dot product calculation explained.
const dot = vectorA.reduce((sum, val, i) => sum + (val * vectorB[i]), 0);
const magnitudeA = Math.sqrt(vectorA.reduce((sum, val) => sum + (val * val), 0));
const magnitudeB = Math.sqrt(vectorB.reduce((sum, val) => sum + (val * val), 0));
return dot / (magnitudeA * magnitudeB);
};
// A new type used for comparing posts to each other.
type ScoredPost = {
slug: string;
score: number;
};
const getSlugToMostRelatedPostsMap = (embeddings: Embedding[]) => {
const slugToMostRelatedPosts: Map<string, ScoredPost[]> = new Map();
for (const a of embeddings) {
const sims: ScoredPost[] = embeddings
.filter(b => b.slug !== a.slug)
.map(b => ({
slug: b.slug,
score: getCosineSimilarity(a.vector, b.vector), // This is where the cosine similarity calculation comes in.
}))
.sort((a, b) => b.score - a.score)
.slice(0, 3);
slugToMostRelatedPosts.set(a.slug, sims);
}
return slugToMostRelatedPosts;
};
The function getSlugToMostRelatedPostsMap returns a map of slugs (represented as strings) to the most related posts. This map can be used to then retrieve the most relevant Post objects for a given post. Going back to tags-and-posts.ts, here’s how I integrated the new function:
// src/utils/tags-and-posts.ts
// ... At this point, we’ve created an array of embeddings.
const slugToRelatedPosts: Map<string, ScoredPost[]> = getSlugToMostRelatedPostsMap(embeddings);
const getRelatedPostsFromSlug = (slug: string) => {
const similarScoredPosts = new Set(slugToRelatedPosts.get(slug)?.map(scoredPost => scoredPost.slug) || []);
const related: Post[] = [];
for (const post of posts) {
if (similarScoredPosts.has(post.id)) {
related.push(post);
}
}
return related;
};
The getRelatedPostsFromSlug function can now retrieve the most similar posts for a given slug (aka id property). With all the necessary calculations and functions ready, we can display the results on the site.
Displaying Related Posts in Astro
To display related posts, I first created a new Astro component file called src/components/blog/SimilarPosts.astro:
---
import { getRelatedPostsFromSlug, type Post } from '@content/tags-and-posts';
import HeroImage from './HeroImage.astro';
interface Props {
post: Post;
}
const { post } = Astro.props;
const posts: Post[] = getRelatedPostsFromSlug(post.id);
---
{posts.length > 0 && (
<section class="section">
<h2 class="title is-4 has-text-centered">Similar Posts</h2>
<div class="columns is-multiline">
{posts.map((similarPost, index) => {
const heroImage = similarPost.data.heroImage;
return (
<div class="column is-one-third">
<div class="card h-100">
<div class="card-image">
<HeroImage
image={heroImage}
alt={similarPost.data.heroImageAlt}
loading="lazy"
isThumbnail={true}
/>
</div>
<div class="card-content">
<h3 class="title is-5 mb-2">
<a class="title-link" href={`/blog/${similarPost.id}/`}>
{similarPost.data.title}
</a>
</h3>
<p class="is-size-6">{similarPost.data.description}</p>
</div>
</div>
</div>
);
})}
</div>
</section>
)}
The actual UI of this is similar to the Hashnode one since I’m displaying three posts in a row with the image at the top of the card. However, mine does not display the author since all the posts on the site are written by me.
Finally, I added the new component to the bottom of my blog posts. The component was added to the file src/pages/blog/[id].astro which is the file used to generate the page for each post. I won’t show the whole file because it’s too large, but here’s what the code looks like:
---
// ...
export async function getStaticPaths() {
return POSTS.map((post: Post) => ({
params: { id: post.id },
props: { post },
}));
}
const { post } = Astro.props;
// ...
---
<!-- ... -->
<SimilarPosts post={post} />
Lastly, here’s a screenshot of what the new component looks like in the browser:
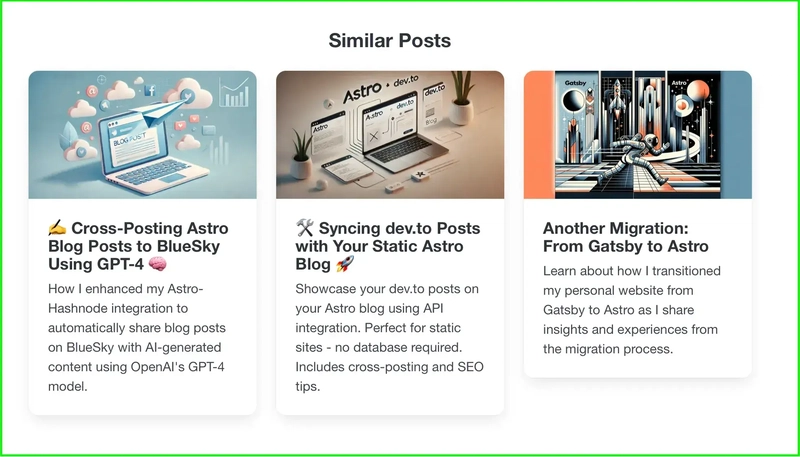
Conclusion
This “Similar Posts” feature is a small but meaningful upgrade that improves content discovery without sacrificing the simplicity of a static site. By precomputing embeddings and using cosine similarity, I was able to generate AI-powered recommendations that are fast, relevant, and completely server-free. It’s a great example of how practical AI tooling can enhance the developer experience — even in static site projects.