
The arrival of powerful Large Language Models (LLMs) has been a shot of adrenaline for developers worldwide. From coding assistants to content generators, the possibilities seem endless. But as the initial excitement settles, a new reality often dawns: the steadily climbing API bills from cloud-based AI services. If you’ve ever felt that pang of anxiety watching your token usage soar, you’re not alone.
The good news? There’s a powerful, cost-effective, and increasingly accessible alternative: running LLMs locally, right on your macOS machine. And with tools like ServBay simplifying the setup, the economics of local AI are looking better than ever for Mac developers.

The Hidden (and Not-So-Hidden) Costs of Cloud LLM APIs
Let’s be clear: cloud LLM APIs from providers like OpenAI, Anthropic, and Google offer incredible power and convenience. But this convenience often comes with a recurring price tag that can significantly impact your development budget, especially during experimentation, prototyping, or for personal projects.
The costs aren’t always just about per-token fees:
- Direct API Costs: These are the most obvious – you pay for the number of tokens processed (both input and output), the specific model used (more powerful models cost more), and sometimes monthly subscription tiers for higher rate limits or premium features. These can add up incredibly fast, especially with iterative development or applications that make frequent calls.
- Throttling & Rate Limits: Free or lower-cost tiers often come with strict rate limits, which can stall your development or force premature upgrades.
- Experimentation Tax: Want to try out five different models for a task or fine-tune prompts extensively? Each iteration on a cloud API can feel like the meter is running, potentially stifling creative exploration.
- Vendor Lock-in: Building your entire AI workflow around a specific proprietary cloud API can lead to vendor lock-in, making it harder to switch if prices increase or services change.
- Latency & Productivity: While often fast, network latency to cloud servers can introduce slight delays. For highly interactive AI tools, these milliseconds matter and can affect user experience or developer flow.
- Data Privacy Concerns: Sending potentially sensitive data or proprietary code to third-party servers is a concern for many. While providers have security measures, the most private data is data that never leaves your machine.
The cumulative effect? Innovation can be hampered by the constant awareness of an ever-ticking financial meter.
The Local LLM Revolution: Taking Back Control (and Your Wallet)
Enter the exciting world of local LLMs. Thanks to significant advancements in model optimization and the availability of powerful open-source alternatives, running capable LLMs on your personal hardware, especially modern Macs with M-series chips, is not just possible but increasingly practical.
Consider these economic game-changers:
- Zero Per-Use Inference Costs: Once you’ve downloaded an open-source model (many, like various Llama models, Mistral, or Phi-3, are free to use), running inferences (i.e., prompting the model) on your local machine costs you nothing in API fees. You can experiment, generate text, or debug code as much as you need.
- Privacy by Default: Your data, your prompts, your intellectual property – it all stays on your machine. This is a massive win for sensitive projects or simply for peace of mind.
- Offline Capability: No internet? No problem. Your local LLM works perfectly offline, ensuring uninterrupted productivity.
- Unleashed Experimentation: Try different models, tweak parameters, and run extensive tests without watching an API bill grow. This freedom is invaluable for learning and innovation.
Tools like Ollama have made downloading and running these open-source models incredibly straightforward via the command line. But what if you want an even more integrated and user-friendly experience on your Mac?
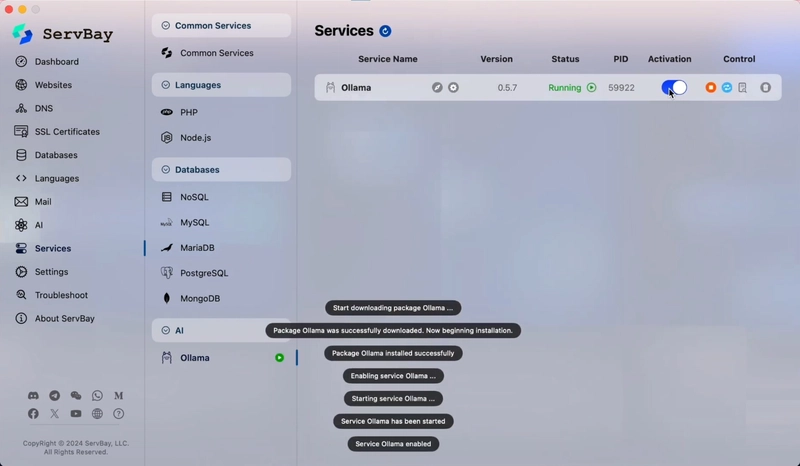
Enter ServBay: Making Local LLMs Economically Viable and Easy on macOS
While tools like Ollama are fantastic, managing different services and ensuring everything plays nicely together in your development environment can still involve some setup. This is where ServBay steps in to make local AI development on macOS not just cost-effective, but also incredibly convenient.
ServBay is an all-in-one macOS local development environment that simplifies managing web servers, databases, multiple PHP/Node.js/Python versions, and much more. Crucially, it now offers seamless Ollama integration.
Here’s how ServBay changes the economics and ease-of-use for local LLMs:
- One-Click Ollama Setup: Forget manual installations and configurations. Within ServBay’s intuitive interface, you can enable Ollama with a single click. ServBay handles the rest, getting you ready to download and run models in minutes.
- Unified Management: Control your Ollama instance, download new models, and manage your local LLMs alongside all your other dev services (Nginx, Apache, MySQL, PostgreSQL, etc.) from one central dashboard. This streamlined workflow saves you time, and developer time is money.
- No Added Cost (for Ollama Integration): Accessing and managing Ollama through ServBay is part of its comprehensive toolkit, allowing you to leverage this powerful AI capability without an extra price tag on top of ServBay itself (check ServBay’s current offerings for any Pro features).
By removing the setup friction and providing a managed environment, ServBay ensures that your journey into local LLMs is smooth, allowing you to focus on leveraging the AI rather than wrestling with the setup – a direct boost to productivity and indirect cost saving.
Real-World Scenarios: Where Local LLMs on ServBay Save You Money
The financial benefits become crystal clear when you consider common development tasks:
- Rapid Prototyping & Iteration: Building a new AI-powered feature? Test dozens of prompt variations, model responses, and integration points locally without incurring any API costs for each test.
- Content Generation (Drafts): Need to generate boilerplate code, draft documentation, or brainstorm ideas? Use your local LLM extensively without limits.
- Continuous Integration/Testing: If your CI/CD pipeline involves testing AI components, using a local model (where feasible for certain test types) can cut down on API calls made by test runners.
- Personal Learning & Exploration: Dive deep into different LLMs, understand their nuances, and build personal projects without financial barriers.
- Small Teams & Startups: Access powerful AI capabilities that might otherwise be prohibitively expensive through cloud API subscriptions, leveling the playing field.
Imagine redirecting the budget previously earmarked for AI API calls towards other critical development tools, resources, or even team growth.
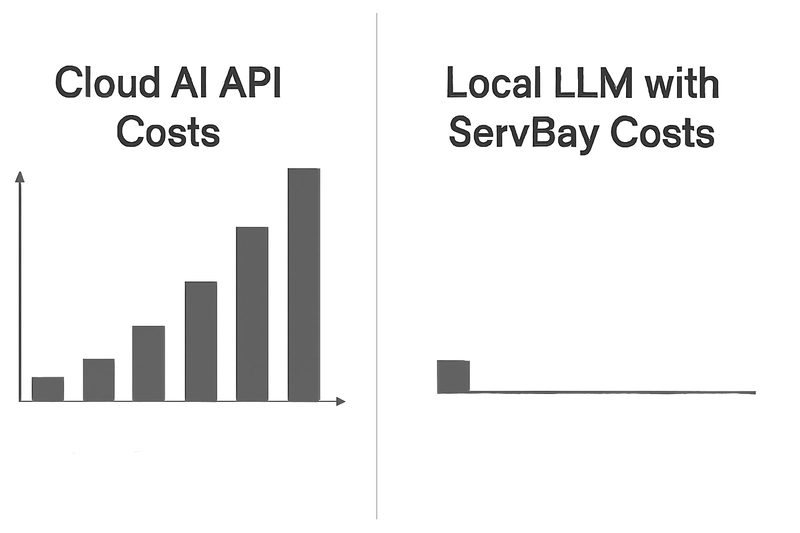
Calculating the Savings (It Adds Up!)
While your Mac’s initial hardware cost is a factor, it’s an existing resource for most developers. The key saving is the marginal cost of running an inference locally, which is effectively zero (beyond electricity) compared to per-token API charges.
Consider a scenario:
- Cloud API: 1 million tokens processed for development/testing in a month could cost anywhere from a few dollars to tens or even hundreds, depending on the model.
- Local LLM with ServBay: After the one-time (free) download of an open-source model, processing those same 1 million tokens (or 10 million, or 100 million) for local tasks costs you $0 in API fees.
The savings can be substantial, especially for ongoing development and heavy experimentation.
Beyond Cost: The Invaluable Extras
The economic argument for local LLMs via ServBay is compelling, but the benefits don’t stop at your bank balance:
- Unmatched Privacy & Security: Your data never leaves your Mac.
- Blazing Speed: Enjoy near-instant responses with no network latency.
- Offline Access: Work anywhere, anytime.
- Full Control: Customize your setup and use models without external restrictions.
These qualitative benefits add immense value, making the local approach even more attractive.
Conclusion: Reclaim Your AI Budget and Your Freedom
The era of being tethered to expensive, metered cloud LLM APIs for every AI task is evolving. With powerful open-source models, tools like Ollama, and simplifying platforms like ServBay, macOS developers now have a clear path to harnessing AI locally.
By shifting appropriate AI workloads to your local machine, you not only drastically reduce or eliminate AI API bills but also gain unparalleled privacy, speed, and control. It’s time to make your Mac the true powerhouse of your AI-driven development.
Ready to stop watching the token meter and start innovating freely? Download ServBay, enable Ollama with a click, and experience the economic and operational freedom of local LLMs on your macOS today!