The Role of Synthetic Data in AI Model Training
Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing industries with smart automation, predictive analytics, and larger scale AI-enabled decisions, but any AI production deployment is only as good as the real-world data it was trained on. Historically, AI training is typically achieved with real data, containing the particular factors within the data, with the intention of mimicking real-world scenarios. Identifying, collecting, cleaning and working to acquire, clean, and label large amounts of data is costly, time-consuming, and with restrictions set by privacy responsibilities. To address this, many organizations are now turning to synthetic data generation.
Synthetic data is not created from the real world; synthetic data is artificially made based on algorithms, a replication of real-world scenario, or any other computer simulation or generative AI model. When used correctly, synthetic datasets are able to benchmark the use-case scenarios of real-world dataset, but they will provide more scale and flexibility. Synthetic data, is becoming a key business enabler for businesses and researchers in the build of trustworthy, ethical and reliable AI models.
What is Synthetic Data?
Synthetic data refers to data that is generated artificially that mimics the statistical properties of real-world datasets. Synthetic data is generated through simulation software and rules-based systems and GANs (generative adversarial networks) and results in text output and image and video output and structured data.
Synthetic data differs from anonymized real data in that it is generated from random noise and fully synthetic. Because of this distinction, it promotes privacy and allows for the training of different model inputs computing in real datasets.
Why Synthetic Data Matters in AI Model Training
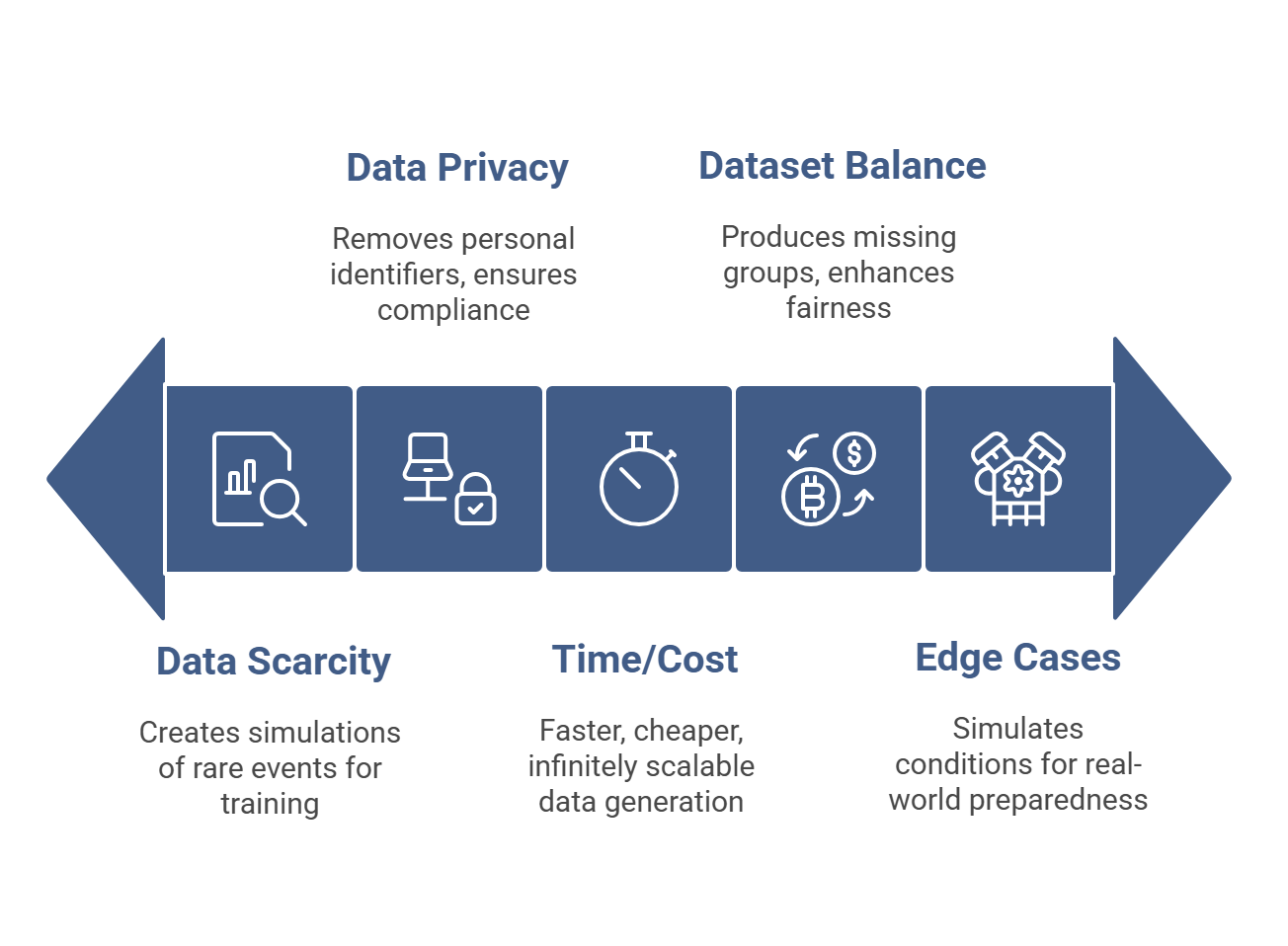
1. Battling Data Scarcity
A major culprit for the high failure rates of AI projects is the lack of enough data. When dealing with rare events, like fraudulent transactions or rare diseases, aggregating a large enough dataset to work with is difficult. By leveraging synthetic data, development teams can create simulations of rare events which can help train models with those events.
2. Data Privacy and Compliance
Real-world data is difficult to collect because it usually comes with personal information and the business has a requirement to follow GDPR and HIPAA regulations. Synthetic data, on the other hand, is void of any personal identifiers by design so businesses can train models with assurance of not having privacy risks.
3. Good for Time and Cost Reduction
Searching on-line for millions of data points through collection, cleaning and annotating is a long process that takes months, and valuable budget dollars. The synthetic data generation process is much quicker, low cost and has infinite scalability.
4. Balancing Datasets
Real-world datasets contain systematic biases together with unbalanced data distribution. The facial recognition dataset contains an unbalanced demographic distribution because it shows more of certain groups than others. The process of generating synthetic data enables developers to produce missing demographic groups which enhances both fairness and inclusivity in their datasets.
5. Supporting Edge Cases and Simulations
Autonomous driving applications face an insurmountable challenge when attempting to test all possible real-world driving scenarios including adverse weather and dim lighting and abnormal road conditions. The use of synthetic environments allows models to learn from simulated conditions which helps them develop preparedness for unpredictable real-world situations.
Applications of Synthetic Data in AI Training
Healthcare Organizations – The development of diagnostic devices that protect patient privacy requires healthcare organizations to produce artificial medical records and image datasets including MRI scans.
Finance –The protection of consumer privacy through synthetic transaction data enables better fraud detection systems and risk rating models.
Retailers and eCommerce Companies – Synthetic datasets enable retailers and eCommerce companies to develop recommendation systems that match consumer needs and visual product recognition systems for tagging products.
Automotive (Autonomous Vehicles) – The training of decision-making algorithms and object detection systems for autonomous vehicles requires simulated environments to produce millions of labeled images and video sequences.
Cybersecurity – AI models receive synthetic data for security threat detection during training which enables them to identify anomalies without triggering actual system breaches.
Challenges of Using Synthetic Data
Utilizing synthetic data has numerous advantages, but there are several key limitations.
Quality Concerns -The synthetic data will only affect performance of the AI model based on what it learns; poor representations of a real-world situation will degrade model performance upon deployment.
Bias Replication – The production of synthetic data may continue and intensify existing discriminatory patterns rather than eliminate them, when the production of synthetic data does not employ acceptable quality control.
Validation Issues – Models trained on synthetic data still need testing against real-world datasets to ensure accuracy and reliability.
Complexity of Generation -Advanced methods like GANs require expertise and significant computational resources to produce high-quality data.
Best Practices for Leveraging Synthetic Data
1. Combine Synthetic and Real Data – The combination of synthetic data with real datasets produces the most dependable results in hybrid approaches.
2. Validate Against Real-World Scenarios – The process of continuous benchmarking helps models learn to perform well when they encounter real-world data.
3. Invest in Quality Generation Tools – Organizations should implement sophisticated generative AI models and simulation platforms that produce diverse realistic datasets.
4. Focus on Fairness and Diversity – Synthetic data generation systems should incorporate fairness and diversity standards to achieve better AI ethics and reduce bias.
5. Maintain Domain Expertise – Subject matter experts should participate in the process to guarantee synthetic datasets match the problem requirements and maintain accurate context.
The Future of Synthetic Data in AI
Organizations will make synthetic data their fundamental building block for AI development because they need to handle privacy issues, data collection expenses and obtain extensive datasets. The next few years will see analysts forecast that AI models will use synthetic datasets as their main or supplementary AI training data source.
The development of generative AI through diffusion models, enhanced GAN architectures will create synthetic data that becomes more authentic and dependable. The combination of synthetic data with ethical standards and privacy protection will enable businesses to speed up their innovation process.
Conclusion
Synthetic data has evolved from being an auxiliary tool to become a fundamental requirement for training AI models. Synthetic data provides businesses with the ability to maximize AI potential through its capabilities to decrease costs and safeguard privacy and handle data shortages and discriminatory patterns.
Organizations that follow best practices when merging synthetic data with real-world inputs will develop AI models which are smarter and robust. Synthetic data has become the transformative element which will define the future development of artificial intelligence because it serves as the fuel for intelligence in our data-driven world.
The post The Role of Synthetic Data in AI Model Training appeared first on Datafloq.