
350PB, Millions of Events, One System: Inside Uber’s Cross-Region Data Lake and Disaster Recovery
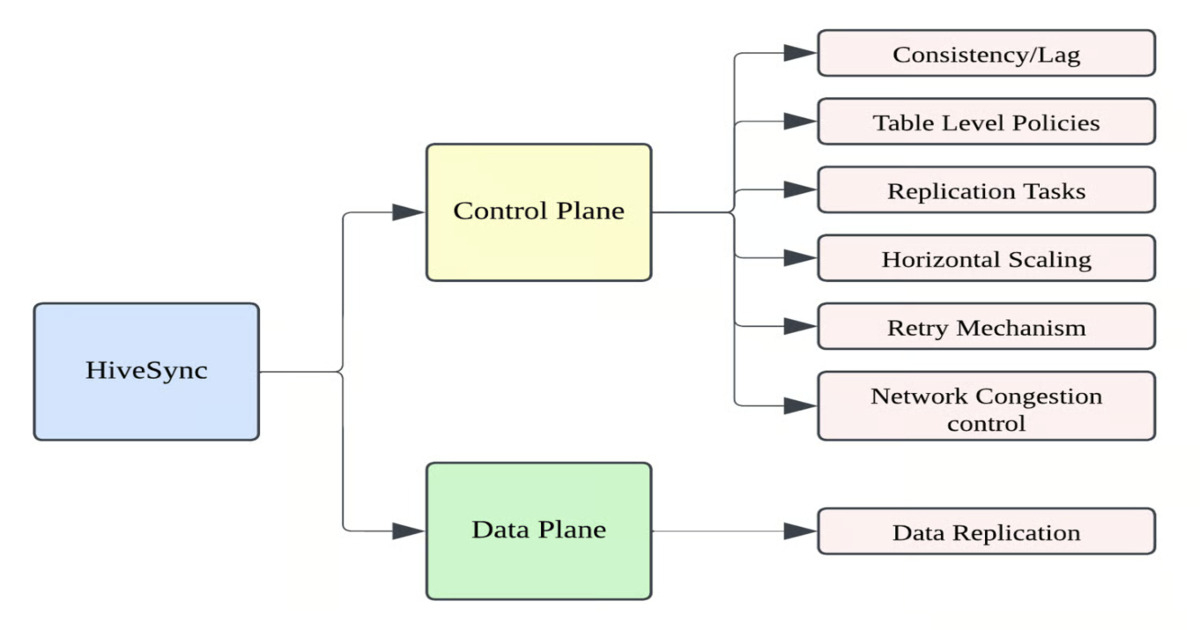
Uber’s HiveSync is a sharded, cross-region batch replication system keeping Hive/HDFS data consistent across multiple regions. Handling 5M daily Hive events and 8PB of data replication, it uses event-driven jobs, hybrid RPC and DistCp strategies, DAG-based orchestration, and dynamic sharding, enabling disaster recovery, horizontal scaling, and 99.99% cross-region data accuracy.
By Leela Kumili


